
Classification Metrics? Let me explain
Accuracy, Precision, Recall and F-1

Hey there, and welcome back to another episode of “The Random ML Guy”! Today, we’re diving into the various metrics used in classification machine learning problems. Whether you’re predicting if an email is spam or not, or classifying images of cats and dogs, these metrics will tell you exactly how well your model is performing.
We’ll cover:
Accuracy
Precision
Recall
F-1 Score
Let’s explore each of these metrics in detail, discuss their pros and cons, and see some code examples to make things crystal clear.
What is Accuracy?
Accuracy is perhaps the most straightforward classification metric. It measures the ratio of correctly predicted instances to the total instances. In simple terms, it tells you how often your model is correct.

Example: Imagine you have a dataset of 100 emails, 80 of which are spam and 20 are not. If your model correctly predicts 70 spam emails and 15 non-spam emails, your accuracy would be:
Accuracy = (70 + 15) / 100 = 0.85 or 85%Code Example:
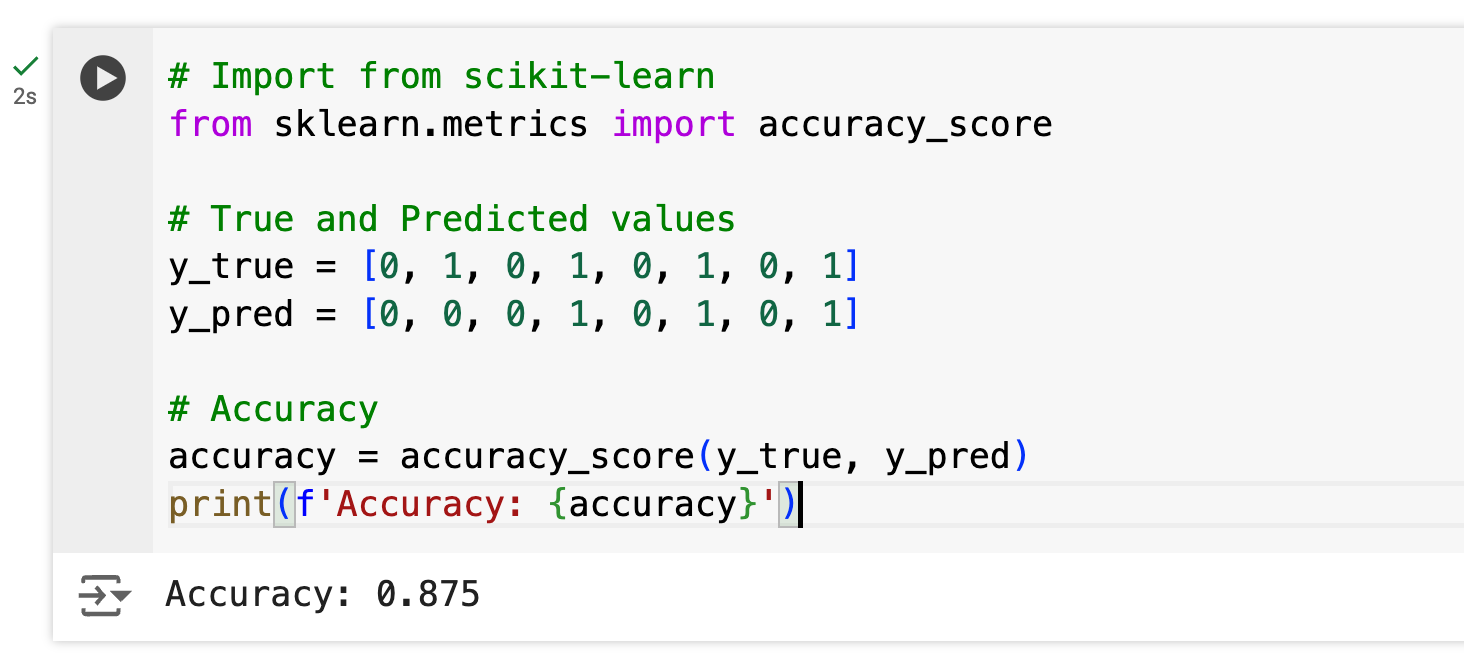
Pros:
Simple to understand and calculate.
Provides a quick snapshot of model performance.
Cons:
Misleading with imbalanced datasets. For example, if 95% of emails are spam, a model that always predicts spam will have 95% accuracy but is not useful.
Want to dive deeper? Check out this blogpost on accuracy in Machine Learning
What is Precision?
Precision measures the ratio of correctly predicted positive observations to the total predicted positives. It answers the question: “Of all the instances the model predicted as positive, how many were actually positive?”

Example: Using the email spam example, if your model predicts 60 emails as spam, and 50 of them are actually spam, then:
Precision = 50 / 60 = 0.83 or 83%Code Example:

Pros:
Important when the cost of false positives is high. For example, in medical diagnosis, predicting a disease when it is not present can lead to unnecessary treatments.
Cons:
Ignores false negatives, which can be problematic if the cost of missing a positive instance is high.
What is Recall?
Recall, also known as sensitivity, measures the ratio of correctly predicted positive observations to all actual positives. It answers the question: “Of all the positive instances in the dataset, how many did the model correctly identify?”

Example: Continuing with the email spam example, if there are 80 spam emails and your model correctly identifies 70 of them, then:
Recall = 70 / 80 = 0.875 or 87.5%Code Example:
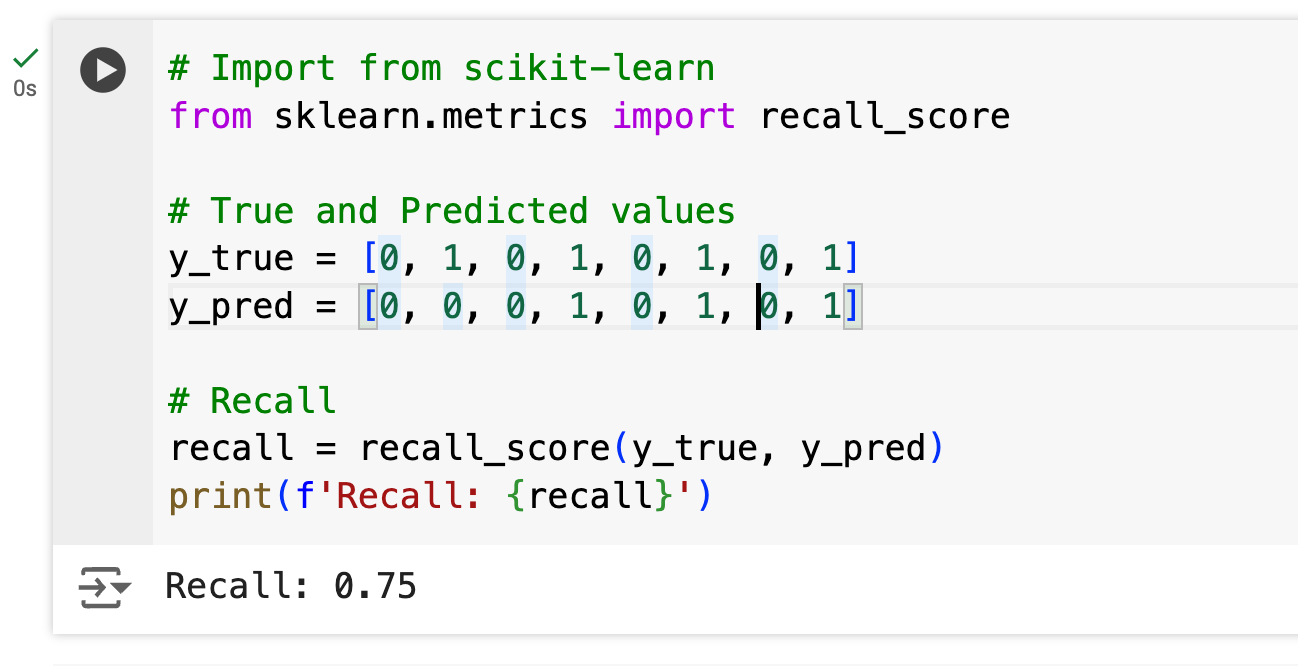
Pros:
Essential when the cost of false negatives is high. For instance, in fraud detection, missing a fraudulent transaction can be very costly.
Cons:
Ignores false positives, which might be problematic in some contexts.
To learn more on precision and recall, have a look at this article by Google.
What is the F-1 Score?
The F-1 Score is the harmonic mean of Precision and Recall. It provides a balance between the two metrics and is particularly useful when there is an uneven class distribution.
Example: If a model has a Precision of 0.75 and a Recall of 0.60, then the F-1 Score would be:
F-1 Score = 2 * (0.75 * 0.60) / (0.75 + 0.60) = 0.6667 or 66.67%Code Example:
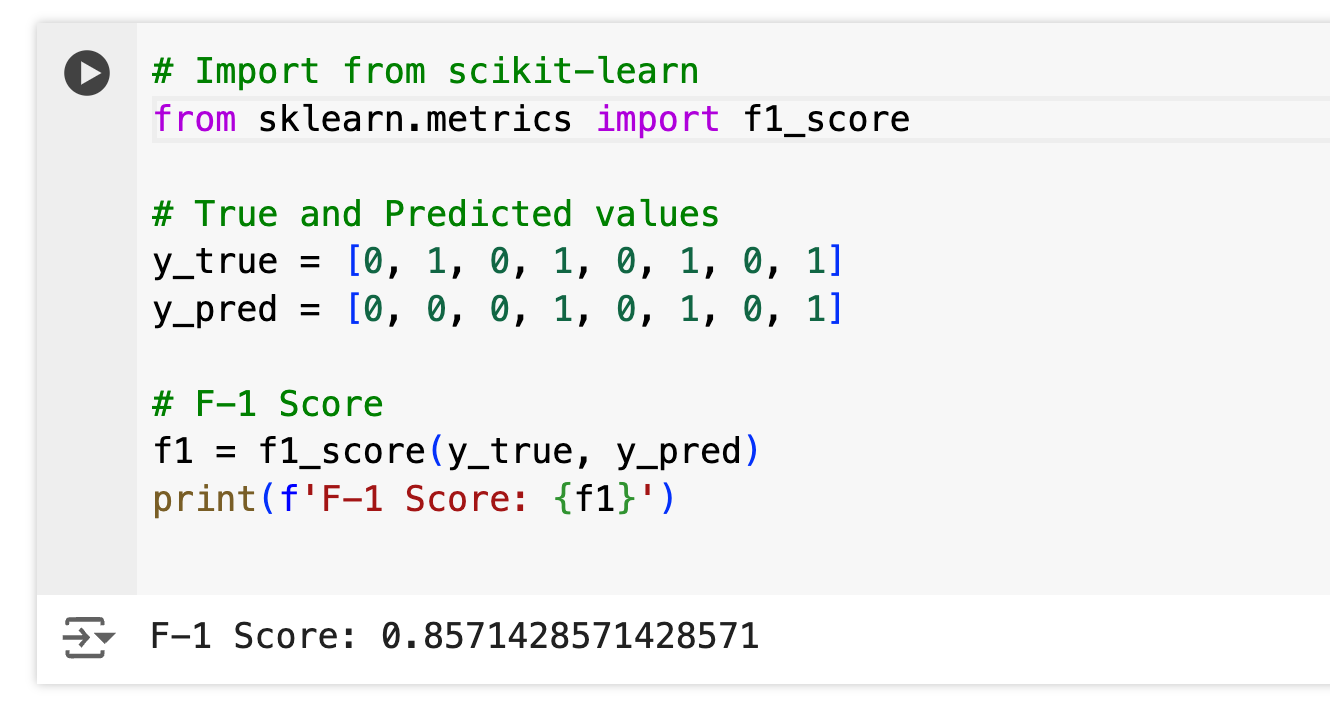
Pros:
Balances Precision and Recall, providing a single metric that considers both types of errors.
Useful for imbalanced datasets.
Cons:
Can be misleading if there is a significant imbalance between Precision and Recall.
May not provide a complete picture when used alone.
To learn more about the F-1 score, have a look at this post by GeeksForGeeks.
Conclusion
In this article, we’ve covered the key metrics used in evaluating classification models, including Accuracy, Precision, Recall, F-1 Score, and classification reports in scikit-learn. Each metric has its strengths and weaknesses, making it important to choose the right metric based on the specific context and requirements of the problem at hand.
Choosing the right evaluation metric is crucial for understanding your model’s performance and making informed decisions to improve it. For instance, if you’re working on a medical diagnosis problem where false negatives are costly, Recall might be more important than Precision. On the other hand, if you’re dealing with email spam detection where false positives (marking a legitimate email as spam) are more problematic, Precision would be more relevant.
Final Thoughts:
Accuracy is great for balanced datasets but can be misleading for imbalanced ones.
Precision is vital when the cost of false positives is high.
Recall is crucial when missing a positive instance is costly.
F-1 Score provides a balance between Precision and Recall, especially useful for imbalanced datasets.
By understanding and applying these metrics appropriately, you can better evaluate your machine learning models and improve their performance.
So folks, that’s it for today — hope you enjoyed the read and if you did, be sure to give me a follow (:
Signing out,
Cheers,
The random ML guy